Das Konzept der “Baseline” ist fest in der IT Infrastructure Library (ITIL) verankert. Selbsterklärend ist es nicht. Und wenn wir versuchen, den Begriff mit “Basislinie” oder “Messbasis” einzudeutschen, wird es nicht klarer. Darum schauen wir uns das Konzept der ITIL Baselines an. Wir zeigen Ihnen, was es damit aufsich hat und wie Sie es mit i-doit und der Netzwerk-Discovery umsetzen können.
Woher kommt das Konzept der Baseline?
Zuerst wurde der Begriff des Baselining in Großbritannien Ende der 1980er Jahre benutzt. Damals wurde er in der Version 1 der IT Infrastructure Library (ITIL) niedergeschrieben. Und auch heute noch taucht der Begriff an mehreren Stellen der ITIL-Literatur auf.
Welche Arten von Baselines gibt es?
Die ITIL-Dokumente beschreiben nicht nur eine Art der Baseline, sondern gleich drei.
- Die ITSM-Baseline bildet den Ausgangspunkt von Maßnahmen zur Verbesserung von Services, ab dem die Wirksamkeit dieser Maßnahmen gemessen wird.
- Die Performance-Baseline wird als Startpunkt für die Messung und spätere Bewertung der Performance von Services definiert.
- Die Configuration-Baseline wird als bekannter und definierter Zustand einer Konfiguration beschrieben. Zu diesem kann z. B. zurückgekehrt werden, wenn Changes oder Releases fehlschlagen. Hier werden Snapshots erwähnt. Es wird darauf hingewiesen, dass Baselines einem manuellen oder digital erhobenem Snapshot entsprechen. Nicht jeder Snapshot ist jedoch auch eine Baseline.
Bis zu diesem Punkt klingt alles noch einfach. Im Folgenden beschäftigen wir uns hauptsächlich mit der Configuration Baseline und ihrer praktischen Anwendung im IT-Betrieb.
Bevor wir dies tun, werfen wir noch einen Blick auf den Begriff “Configuration”. Wenn Sie verstanden haben, worum es sich dabei handelt, werden die weiteren Beispiele noch anschaulicher.
Der Begriff “Configuration”
Was im ersten Augenblick nach einer Übersetzung des deutschen Wortes “Konfiguration” aussieht, beinhaltet viel mehr. Denn es handelt sich nicht einfach um eine definierte Zusammenstellung von Hard- und Softwarekomponenten.
Das ITIL-Glossar sagt an dieser Stelle:
“Eine allgemeine Bezeichnung für eine Gruppe von Configuration Items, die zusammen für die Erbringung eines IT-Service oder eines umfangreicheren Teils eines IT-Service eingesetzt werden. Als „Konfiguration“ werden darüber hinaus die Parametereinstellungen für ein oder mehrere CIs bezeichnet.“
Diese Definition wirkt auf den ersten Blick mehr verwirrend als aufklärend. Doch liest sie sich komplizierter als sie ist. Denn sie besagt, dass
- sowohl die Eigenschaften eines einzelnen Configuration Items oder auch
- die Kombination mehrerer Configuration Items, die man für einen Service benötigt
eine Konfiguration darstellen. Ein Configuration Item (CI) ist schließlich die kleinste mögliche Dokumentationseinheit, sozusagen das Atom im Universum der IT-Dokumentation. i-doit bezeichnet diese CIs als “Objekte”.
Die wichtige Frage: Ist der aktuelle Zustand auch der Soll-Zustand?
Möchten Sie eine CMDB im Unternehmen einführen und erstmalig mit Daten beladen, sollten Sie zunächst einige Dinge klären. Allen voran ist die Frage zu beantworten, ob der aktuelle Zustand der IT-Infrastruktur auch tatsächlich “stimmt”. Diese Frage sollte leicht zu beantworten sein. Fragen Sie an verschiedenen Stellen im Unternehmen nach, ist die Antwort jedoch nicht mehr so eindeutig, wie Sie vielleicht denken.
Dazu ein Beispiel:
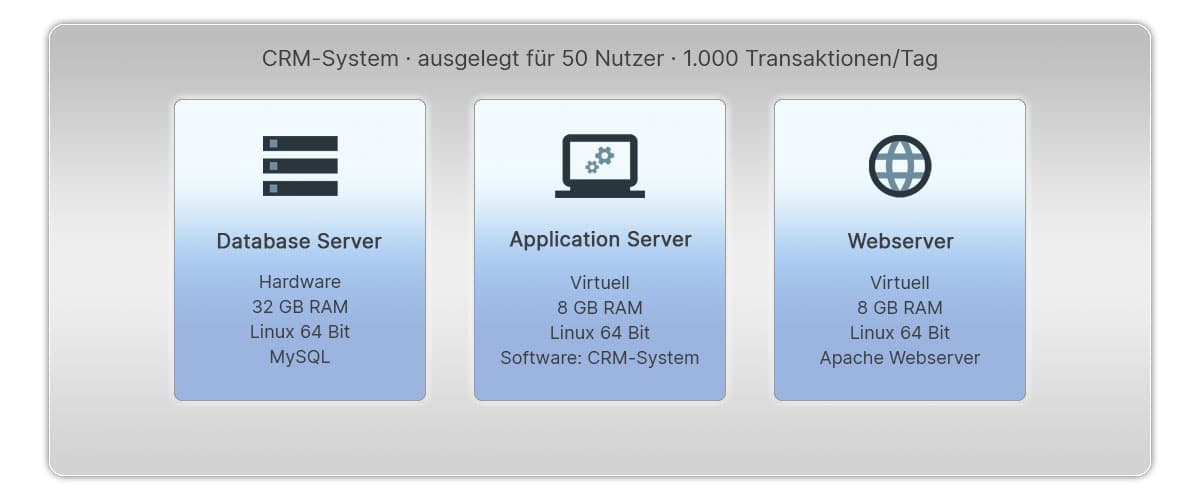
Ein Unternehmen führt eine neue CRM-Software ein. Für dieses Projekt wurde ein Application Server mit 8 GB RAM angefordert. Eine virtuelle Maschine wurde von der IT-Abteilung wie vereinbart bereitgestellt und an die Fachabteilung verrechnet.
In der Projektdokumentation ist der Server in der ursprünglichen Konfiguration beschrieben. Niemand hat diese verändert. Das PDF-Dokument kam von einem externen Dienstleister. Hier handelt es sich um eine Soll-Dokumentation zum Zeitpunkt des Projektstarts. Alle Projektbeteiligten waren zufrieden. SOLL und IST waren gleich.
Nach Abschluss des Projektes wird ein Softwareupdate eingespielt. Es hat sich herausgestellt, dass dafür der Speicher des Application Servers aufgerüstet werden muss. Ihr freundlicher Administrator hat das mit wenigen Mausklicks rasch erledigt. Dem virtuellen Server sind nun 16GB RAM zugewiesen.

Das System läuft zur Zufriedenheit der Anwender. Doch die dokumentierten Informationen driften auseinander. Streng genommen ist das SOLL immer noch mit 8 GB definiert. Die Fachabteilung kennt unter Umständen nicht einmal die Schwierigkeiten, die beim Update aufgetreten sind. Worauf beziehen sich nun die weiteren Prozesse?
Der Administrator wird sagen: “Auf das IST!”.
Idealerweise erinnert er sich im Fehlerfall daran, dass er seinerzeit den Speicher des Application Server auf 16 GB erweitert hat.
Die Fachabteilung (und vielleicht der externe Dienstleister) wird sagen, dass die SOLL-Dokumentation maßgeblich ist. Schließlich war diese Konfiguration der Stand, den alle kannten.
Sie sehen: schon eine Kleinigkeit kann bedeutende Auswirkungen haben.
Nicht ausreichende Dokumentation des SOLL – Zustands
Was geschieht im Fall eines (Aus)Falles?
Bezieht sich der Fehlerbehebungsprozess auf das alte (und einzige) Dokument? Dann stellen Sie – formal vollkommen korrekt – nach einem Ausfall eine alte SOLL-Konfiguration wieder her. Die Applikation funktioniert jedoch nicht. Die Folge sind unnötige Recherche und Zeitverlust bis zur Wiederherstellung des CRM-Service.
Der Grund ist klar: eine nicht ausreichende Dokumentation des SOLL-Zustands.
Eine Diskrepanz im Arbeitsspeicher eines Servers kann bereits zu einem bedeutenden Problem führen. Weitaus kostenintensiver für das Unternehmen können jedoch kleine Änderungen von Konfigurationen sein, wenn sie das Lizenzmanagement berühren. Und wenn erst sicherheitsrelevante Aspekte ins Spiel kommen, können die Folgen einer falschen SOLL-Konfiguration katastrophal sein.
SOLL oder IST ist meist nicht definiert
Den Aufbau und die laufende Pflege einer CMDB übernimmt in der Regel ein Admin. Als Techniker muss man davon ausgehen, dass der aktuelle Status im Netzwerk auch der erwünschte Zustand ist. Schließlich läuft das System. Das bringt ein Problem mit sich. Denn weder IST noch SOLL sind definiert. Es geht einzig um den funktionalen Status. Dieser wird als Grundlage einer Wiederherstellung im Fehlerfall angenommen.
Am einfachsten wird ein solcher Status mit Snapshots von virtuellen Umgebungen oder mit Backups zu fixen Zeitpunkten erstellt. Diese Snapshots sind vermeintlich funktional. Wir haben uns daran gewöhnt, sie nicht weiter zu dokumentieren.
Das gilt gleichermaßen für die Konfiguration eines Netzwerkes. Auch die Software, die auf Clients installiert ist, wird meist vernachlässigt. Dabei spielt es auch keine Rolle, wie sie dorthin gekommen ist. Im besten Fall steht im Backup-Log ein Einzeiler: “Full Backup vom 29.02.2020.”
Fehlende Dokumentation und die Fachabteilungen
Aber wie sehen das die Verantwortlichen der verschiedenen Abteilungen? Wie gehen Budgetverantwortliche, die Buchhaltung, oder die Prozessverantwortlichen mit nicht vorhandener Dokumentation um?
Dokumentieren wir den IST-Zustand nur mittels Snapshot, verpassen wir unter Umständen etwas Wesentliches. Jemand muss für die Differenz der im erwähnten Beispiel zugewiesenen 8GB auch bezahlen. In anderen Fällen muss eine Lizenz angepasst werden. Die SOLL-Dokumentation muss aktualisiert und an die richtigen Personen verteilt werden. Möglicherweise ist auch herauszufinden, warum unser Änderungsprozess es zulässt, dass vom SOLL zum IST plötzlich Unterschiede bestehen.
Das alles ist Grund genug, um im Rahmen eines Projektes über den Umgang mit Versäumnissen und Ungereimtheiten der Vergangenheit zu sprechen. Aber es ist auch Grund genug, eine für alle Beteiligten klar definierte Linie zu setzen. Eine klare Basis muss geschaffen werden, auf die hingearbeitet wird und von der fort gearbeitet wird.
Die Baseline: Gleichstand von Technik und Organisation
Eines dürfte schnell klar werden: Der technische Snapshot allein ist zu wenig. Wir müssen diesen auch Nachbearbeiten, anpassen und mit zusätzlichen Informationen anreichern können. Und in Zukunft wollen wir ihn planen. Und damit sind wir angekommen.
Hier ist die Baseline.
Wir ziehen einen Strich und sagen: Die Ebenen Buchhaltung, Technik, Lizenzen und Dokumentation haben sich auf diese eine Wahrheit geeinigt. Das ist das neue SOLL. Abweichungen, egal aus welchem Grund, darf es nicht geben. Wenn doch, wollen wir sie auch herausfinden und einer Betrachtung unterziehen!
Die Planung der Baselines
Eine Baseline kann durch vieles ausgelöst werden. In unserem Beispiel hat das neue Release der CRM-Software den Grund geliefert, den Speicher des Servers zu erweitern. Damit benötigen wir auch mehr Speicher beim Backup und mehr Zeit beim Rücksichern. Eventuell ist beim Update auch eine neue Version des Webservers installiert worden oder PHP hat eine Aktualisierung erfahren.
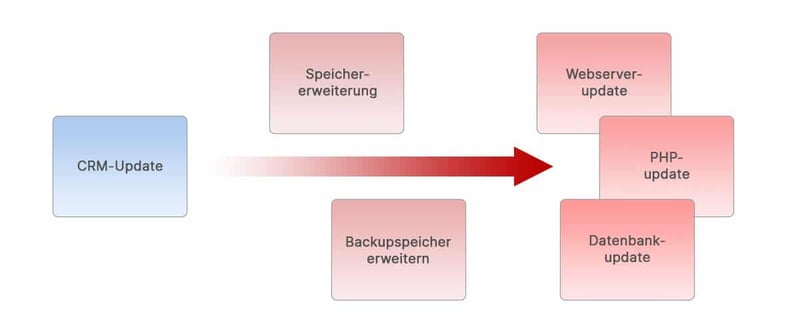
Wurde auch die Datenbank auf den neuesten Stand gebracht? Dann führt dies automatisch bei allen anderen Anwendungen, die am Datenbankcluster mitlaufen, zu Nacharbeiten. Alles zusammen genommen umfasst unsere Baseline “CRM Update Frühjahr 2020” also viele einzelne Punkte. Diese hängen direkt miteinander zusammen und machen eine betriebsinterne Baseline aus. Diese Baseline ist nun unser neues Plan-Soll. Für die Verrechnung, für Backup-Konzepte, das Lizenzmanagement, den Störungsfall und letztlich für unsere gesamte IT-Dokumentation.
Start der Configuration Control
Die erste Baseline definieren Sie bereits mit der Erstaufnahme von Daten in die CMDB. Dabei ist es unerheblich, ob das nun ein offizieller Anlass ist oder nicht. Alle anderen Informationen und Dokumentationen sind von nun an überholt. Sie dürfen streng genommen nur noch als historisches Nachschlagewerk verwendet werden. Sie könnten sie z. B. zum entsprechenden Configuration Item als Hyperlink oder Dokument hinzufügen.
Ab jetzt ist Ihre CMDB das führende System für alle ITSM-Prozesse. Halten Sie sich vor Augen, dass das in die CMDB aufgenommene IST für die Folgeprozesse dem SOLL entspricht. Ausnahme: Sie verifizieren es sofort und passen es gegebenenfalls an.
Diese Ausnahme ist wichtig. Sie zwingt uns dazu, darüber nachzudenken, wie viele Informationen wir auf einmal in die CMDB übertragen. Übernehmen wir direkt alle Daten oder nur das, was wir auch zeitlich vertretbar verifizieren und korrigieren können?
Bei dieser Überlegung ist zu beachten, dass ab Aufnahme in die CMDB alle darin befindlichen CIs unter “Configuration Control” stehen.
Das bedeutet für unser erwähntes Beispiel:
Der Change Management Prozess muss dafür Sorge tragen, dass die gleiche Situation beim nächsten Aufrüsten des Speichers nicht nochmals auftritt. Das gilt für das Überarbeiten der SOLL-Dokumentation, das Auslösen der Verrechnung und auch für die IST-Dokumentation. Welche Daten “einfach so” überschrieben werden dürfen, muss vorher festgelegt sein. Doch dazu später mehr.
ITIL kennt im Übrigen für den Prozess der Erstaufnahme in die CMDB einen eigenen Begriff und definiert diesen wie folgt:
Configuration Identification
Die Aktivität, die für die Sammlung von Informationen zu Configuration Items und deren Beziehungen sowie für das Laden dieser Informationen in die CMDB verantwortlich ist. Bei der Configuration-Identifizierung werden darüber hinaus die CIs selbst mit Bezeichnungen versehen, um eine Suche nach den entsprechenden Configuration Records durchführen zu können.
Baseline mit Discovery-Tools
Die nächste Aufgabe wartet. Sie müssen kurzfristig einen Snapshot der jetzt vorgefundenen Konfiguration anfertigen. Das ist auch bei einem kleinen Netzwerk eine nicht zu unterschätzende Aufgabe. In einem relativ kurzen Zeitfenster sollen die Konfigurationen aus den beteiligten Netzwerkknoten ausgelesen und in eine Datenbank eingegeben werden. Während der Erstaufnahme sollten auch keinerlei Änderungen stattfinden.

Die Aufgabe klingt einfacher als sie ist. Die beteiligten Mitarbeiter müssen sich in die einzelnen Geräte einloggen. Anschließend müssen sie die Konfigurationsdaten identifizieren und auslesen und diese strukturiert (und standardisiert) in einer Datenbank ablegen. Das klingt nach einer Aufgabe, die manuell nur mit hohem Zeitaufwand und einem ausgefeilten Qualitätssicherungsprozess zu leisten ist. Die Korrekturen garantiert auftretender Tippfehler sollten Sie von vornherein mit einkalkulieren.
Diese Informationen auch nur einige Tage aktuell zu halten ist eine anspruchsvolle Herausforderung. Zum Glück kommt hier die Automatisierung in Form von Netzwerk-Discovery ins Spiel. Als Werkzeug der Wahl nutzen wir hier JDisc. Damit sind wir bestens aufgestellt, denn der Hersteller kümmert sich darum, die neuesten Geräte und Standards zeitnah zu unterstützen.
Netzwerk-Discovery mit JDisc

Lassen wir JDisc auf unser Netzwerk los, wird jeder aus DNS, Directory oder ARP-Caches gefundene Netzwerkknoten verifiziert. Mit unterschiedlichen Methoden werden die Konfigurationen der Geräte, die in der Firmware bzw. dem Betriebssystem gespeichert sind, ausgelesen.
Wir gewinnen hierdurch in erster Linie Zeit. Unterschätzen Sie jedoch auch nicht den Qualitätsfaktor. So schnell und fehlerfrei tippt kein Mensch. In Tabellenform werden die Geräte anschließend aufgelistet, können analysiert, gruppiert und nach gewissen Eigenschaften und Konfigurationen sortiert werden.
Gruppen in JDisc bilden
Wir haben die Angewohnheit, in einer Menge von Dingen nach gleichartigen Merkmalen zu suchen, sie zu gruppieren. Diese Angewohnheit können wir bei den durch JDisc erhaltenen Daten nutzen. So können wir den gewaltigen Datenmengen im Netzwerk Herr werden.
Gleichartige Assets wie Notebooks, PCs oder IP-Telefone fassen wir zu Gruppen zusammen. Auch aus IP-Netzen, die geografisch strukturiert sind, werden eigene Scan-Gruppen gebildet. Mit der Kombination aus beidem erhalten wir dynamische Gruppen. So könnten wir Clients in Frankreich und Telefone in den USA gruppieren.
Wir strukturieren also verarbeitbare Datenblöcke bereits im Discovery-Tool. So ermöglichen wir eine Vorqualifizierung der Daten, noch bevor sie in die CMDB gespielt werden. In JDisc können sie vorab auf Vollständigkeit geprüft und dann auf einmal in die CMDB übernommen werden. Die in i-doit integrierte Schnittstelle zu JDisc kann mit dessen Gruppen umgehen.
Nacharbeiten und Verifizierung
Nun beginnen die Nacharbeiten in der CMDB. Die betreffen vor allem das Anreichern mit Daten, die nicht über die Discovery identifiziert werden konnten. Hierzu zählen Verträge, buchhalterische Werte und eindeutige Labels. Diese Arbeit kann im Team verteilt und von entsprechenden regionalen Betreuern abgewickelt werden.
Wichtig: SOLL und IST sollten verifiziert werden.
Sind SOLL und IST nun verifiziert, vollständig und für alle Folgeprozesse freigegeben, sollten Sie das auch bekanntgeben. Wie sollen Ihre Kolleginnen und Kollegen erfahren, dass es sich um verifizierte Daten handelt?
Auch diese Information wird im Datenbestand kenntlich gemacht. Wir benötigen eine Notiz im Verlauf des Lebenszyklus. Das Stichwort lautet hier “Logbuch”.
Erstellen einer Baseline in i-doit
 Als “Notiz” bieten sich die Workflows an, die i-doit mitbringt. Ein eigener Workflow-Typ Baseline ist schnell erstellt. Die Daten, die aus JDisc in die CMDB importiert wurden, werden zu einer Baseline hinzugefügt. Ergänzt werden Sie durch einen aussagekräftigen Text.
Als “Notiz” bieten sich die Workflows an, die i-doit mitbringt. Ein eigener Workflow-Typ Baseline ist schnell erstellt. Die Daten, die aus JDisc in die CMDB importiert wurden, werden zu einer Baseline hinzugefügt. Ergänzt werden Sie durch einen aussagekräftigen Text.
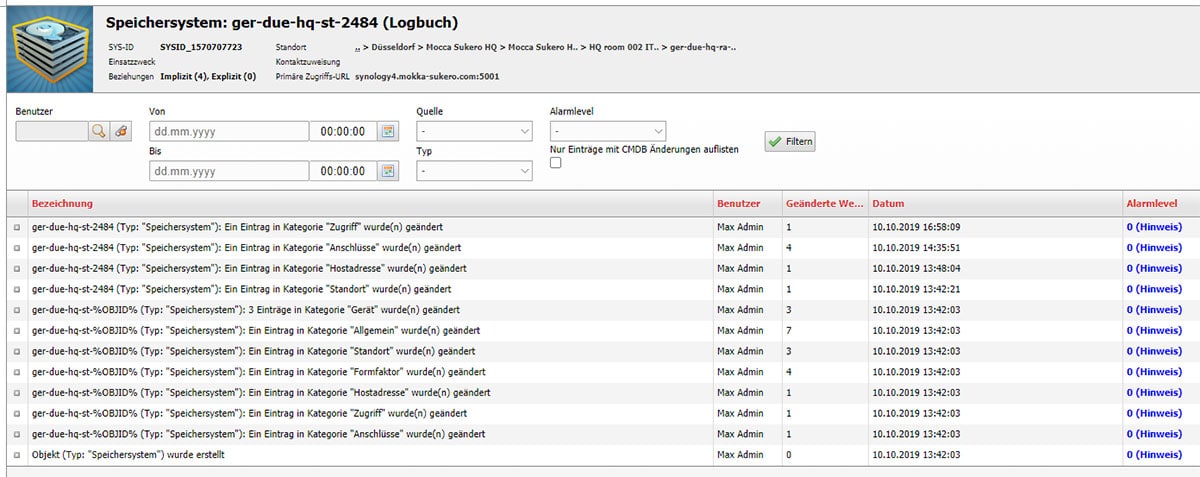
Ist der vereinbarte Vorgang durchgeführt, wird die Aufgabe auf “erledigt” gesetzt. Jede Aktion führt zu einem Eintrag bei den betroffenen Objekten. Der Screenshot zeigt uns die LOG-Einträge eines einzelnen Objekts, die für alle späteren Leser nachvollziehbar sind.
Der Prozess zur Datenübernahme von Assets
Wenn Daten in die CMDB übernommen werden sollen, folgen wir einem festgelegten Prozess. Dieser kann wie folgt aussehen:
- Ankündigung einer Änderung. Hinweis, dass SOLL und IST voneinander abweichen können.
- Änderungen an den Geräten werden durchgeführt (Update, neue Hardware etc.)
- Scan mit JDisc und Übernahme des neuen IST
- Übernahme des neuen IST in die CMDB
- Verifizieren der Daten in der CMDB, SOLL und IST werden gleichgesetzt
- Eventuelle Anpassungen im IST durchführen. Punkt 3 wiederholen.
- Abschließen der Änderungen. Die neue Configuration Baseline ist nun gültig und steht ab sofort unter Configuration Control. Änderungen dürfen nun nicht mehr stattfinden.
Das alles klingt bisher sehr einfach. Es könnte der Eindruck entstehen, dass das Zusammenspiel von CMDB und Discovery alle Probleme löst. Doch dies ist nicht so, wie sich noch zeigen wird.
Eine Konfiguration ist mehr als Discovery leisten kann
Ziehen wir noch einmal das Beispiel unseres CRM-Systems heran. Auf den ersten Blick haben wir nun alle zugehörigen Daten in die CMDB übertragen. Das System funktioniert und die Anwender sind zufrieden.
Die CMDB kann Ihnen jedoch das Denken nicht abnehmen. Wenn wir wissen wollen, was zum IT-Verbund des CRM-Services gehört, kann uns die CMDB nur bedingt Antwort geben. Hier ist noch mehr der Mensch als die Maschine gefragt.
Bereits die Definition der Configuration weist darauf hin, dass es nicht nur um die Eigenschaften einzelner CIs geht. Auch die Abhängigkeiten zwischen ihnen sind von Bedeutung. Es geht um den Verbund mehrerer technischer und von Menschen erbrachter Dienste. Dieser Verbund ermöglicht erst den durch die Anwender genutzten Service. Wie kann nun die Discovery dabei helfen, eine Service-Konfiguration festzustellen? Und wo liegen die Grenzen dieser Technologie?
Die Discovery kann erkennen, nicht interpretieren
In den Daten, die uns das Discovery-System liefert, befinden sich auch die drei Server, die wir näher betrachten. Wir Menschen wissen (oder können ableiten), dass diese für unseren CRM-Service die Rolle Datenbankserver, Application-Server und Webserver ausfüllen.
Auch die Discovery kennt entsprechende Hinweise. Das System kann laufende Dienste, Services und Daemons erkennen. Das bedeutet jedoch nicht, dass ein Dienst, der auf einem Server läuft, auch erwünscht oder notwendig ist. Auch wissen die Dienste in der Regel nicht, für wen sie angeboten werden.
Wir müssen den Systemen mitteilen, dass der übergeordnete Service der CRM-Service ist. Maschinen können das nicht erkennen. Der Discovery-Lösung geht es nicht anders. Denn sie kann sich zwar die Verbindungen zwischen den Geräten ansehen und diese analysieren. Die Netzwerktopologie kann analysiert und aufgezeichnet werden. Aber die Interpretation bleibt uns Menschen vorbehalten.
Discovery der Netzwerk-Topologie
Es bietet sich nun eine verlockende Möglichkeit. Wir könnten mit der Hilfe einer automatisch ausgeführten Analyse der Netzwerktopologie den CRM-Service dokumentieren. Aber es gibt eine Unschärfe, die wir beachten müssen. Wenn zum Zeitpunkt des Discovery-Laufs zwei Maschinen keine Verbindung haben, heißt das nicht automatisch, dass sie nie verbunden sind. Kommunizieren zwei Server über den Port 1433, können wir annehmen, dass hier ein MS-SQL-Server seine Arbeit verrichtet. Wir wissen es aber nicht. Und auch ein geöffneter Port bedeutet noch lange nicht, dass er auch geöffnet sein soll oder benötigt wird.
Im Ergebnis erspart uns die Discovery enorm viel Analyse-Zeit. Die gewonnenen Informationen geben uns solide Anhaltspunkte und ermöglichen weitere Untersuchungen. Aber als Wahrheit können wir die Daten nicht behandeln. Sollen wir diese Daten nun als IST-Zustand übernehmen oder als SOLL-Zustand? Vorsicht ist angebracht. Wir befinden uns mitten im Mustervergleich. Vom Wissen sind wir noch weit entfernt.
Die Dokumentation von SOLL und IST-Zuständen
Um nun diese vielen Informationen in eine gemeinsame Datenbasis wie die CMDB zu überführen, brauchen wir ein Dokumentationsmodell. Diesem müssen alle Beteiligten folgen können. Es sollte im Idealfall selbsterklärend sein. Einige unterschiedliche Modelle sind in der 7. ITIL Baseline beschrieben.
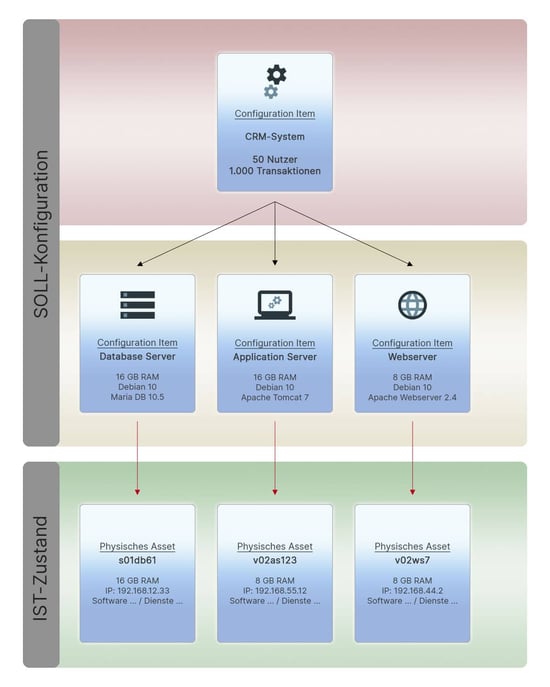
Wir trennen die funktionale Beschreibung und SOLL-Dokumentation von der mit JDisc identifizierten IST-Konfiguration. Und wir definieren folgende Regeln:
- Die SOLL-Konfiguration (in der Grafik die vier oberen Configuration Items) darf nur im Zuge einer Baseline-Planung verändert werden.
- Die IST-Konfiguration (die realen Assets) werden ausschließlich durch Discovery identifiziert und überschrieben. Der oben dargestellte Workflow sorgt für Ordnung.
- Damit wir einen Bezug zwischen SOLL und IST herstellen, diesen analysieren und vergleichen können, verwenden wir die drei (rot dargestellten) manuell herzustellenden Verbindungen.
Folgendes Modell könnten Sie somit problemlos in einer CMDB abbilden:
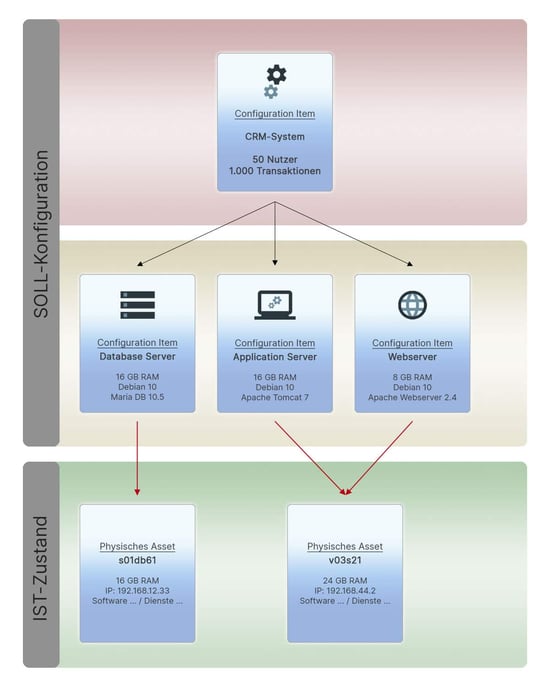
Auch Konfigurationsänderungen wie die folgende sind möglich und selbsterklärend:
Durch die Anwendung dieses Modells haben wir mehrere Vorteile erreicht:
- Discovery-Läufe können beliebig oft durchgeführt werden. JDisc holt sich regelmäßig die IST-Daten aus dem Netzwerk.
- Es sind keine komplexen Regeln beim Überschreiben von Asset-Daten in der CMDB nötig.
- Die Dokumentation des SOLL-Zustands kann unabhängig vom IST zeitgleich in der CMDB stattfinden.
- Eine zeitliche Trennung von SOLL- und IST-Dokumentation ist möglich. Denkbar ist ein Start mit der Übernahme von Discovery (IST), danach Modellieren des SOLL-Zustands. Der umgekehrte Weg ist ebenfalls möglich.
- Kurzfristige Aktionen in der IST-Konfiguration können nachvollzogen werden, verändern jedoch nicht das SOLL.
Die Möglichkeit der Auswertung mit intelligenten Reports (“zeige mir Konfigurations-Abweichungen von Objekten und deren übergeordneten CIs”) ist herausfordernd, aber möglich.
Es gibt jedoch auch einige Nachteile, die wir nicht verschweigen dürfen, z. B.
- mehr dokumentierte Objekte in der CMDB
- IP-Adressen, die im SOLL dokumentiert sind, können nicht mehr frei vergeben werden
Arbeit mit Referenz-Configuration Items
Für Server, Applikationen oder Services ist das eben vorgestellte Modell hervorragend anwendbar. SOLL und IST werden in voneinander getrennten Objekten dokumentiert. Werfen wir jedoch einen Blick auf die Clients, können wir das Modell so nicht mehr anwenden.
Niemand dokumentiert zu jedem Client jeweils ein passendes SOLL-Objekt. Also gehen wir hier pragmatisch vor und arbeiten mit Referenzen. Wir definieren einzelne Configuration Items als Referenz der SOLL-Konfiguration. Auf diese Referenz Configuration Items kann z. B. mit Hilfe eines zusätzlichen Attributs “Link zum SOLL-CI” verwiesen werden.
Vorteile
- Nur ein Referenz-Objekt wird benötigt.
- Das neue Release eines Standardclients und seines Lifecycles kann damit ebenso dokumentiert werden.
Nachteile
- Die Verbindungen müssen ebenfalls von Hand gezogen werden.
- Zusätzliche Dokumentationsobjekte in der CMDB.
Zusammenfassung: Was macht Baselining?
- Eine Configuration Baseline kann aus verschiedenen Gründen erstellt werden. Dazu gehören Veränderungen der Hard- oder Software, ein Massen-Rollout oder auch eine Inventur. Es ist ein Sammelbegriff.
- Eine Baseline stellt eine qualitätsgesicherte, definierte Basis dar, auf die zu einem späteren Zeitpunkt geregelt zurückgekehrt werden kann.
- Die Baseline ist in jedem Falle dokumentationspflichtig. Spätere Prozesse beziehen sich darauf.
- In der Baseline laufen alle Zustände zusammen. Der in der Baseline beschriebene Zustand der Systeme, Applikationen und Konfigurationen ist so erwünscht (SOLL). Er ist in der Realität wie beschrieben (IST). Und er ist auch funktional.
- Die Baseline definiert einen neuen Punkt, ab dem die Configuration Control greift. Änderungen sind nur mit einem Change Request erlaubt.
Herausforderungen des Baselining
- Versuchen Sie nicht, alle Objekte aus JDisc zu übernehmen. Das ist unrealistisch. Die großen Datenmengen können Sie nicht zeitnah qualitätssichern. Sie sollten bereits in JDisc überschaubare Gruppen bilden.
- Rechnen sie damit, dass JDisc nicht alle Geräte zu einem definierten Zeitpunkt erreicht und aktualisieren kann. Arbeiten Sie iterativ und legen Sie – wenn möglich – überschaubare Einheiten fest.
- Das Erreichen einer Baseline muss im Datenbestand der CMDB – z.B. im Logbuch der betroffenen Objekte – ersichtlich sein.
- Eine geplante Baseline unterteilt sich unter Umständen in mehrere Änderungen (Changes, RfCs). Hier sind Verbindungen mit den entsprechenden Einträgen im Change Management System sinnvoll.
Was ist nach dem Erreichen einer Baseline zu tun?
- Dokumentieren Sie die neue Baseline. Bedenken Sie, dass jede Änderung ab sofort kritisch ist.
- Führen Sie Backups von Snapshots und ggf. ganzen Konfigurationen durch.
- Müssen Sie eine schriftliche Gesamtdokumentation überarbeiten? Dann denken Sie bitte daran, diese an die passenden Empfänger zu übermitteln (z. B. externe Beteiligte in Wiederanlaufplänen).
- Denken Sie daran, alle offiziellen Dokumentationen zu aktualisieren. Dies betrifft z.B. Wiederanlaufpläne, Desaster Recovery Pläne oder Systemscheine.
- Reports müssen eventuell erneuert und neu versendet werden.
- Denken Sie daran, notwendige Daten zu exportieren und in eventuell vorhandene Zielsysteme zu importieren, z.B. unternehmensweit eingesetzte Data Warehouses.
- Bestücken Sie externe Dokumentationsplattformen mit den neuen Daten (z.B. USB Sticks, Notfall-Notebooks, Cloud-Speicher)
- Ist der Bereich Informationssicherheit betroffen, wird sehr wahrscheinlich ein Audit fällig.
- Denken Sie an weitere Stakeholder. Auch diese müssen offizielle Informationen erhalten.
Starten Sie mit Ihrer ersten Baseline
Fühlen Sie sich bereit für Ihre erste Baseline? Wir sind sicher, dass Sie mit der optimalen Kombination von JDisc und i-doit einen leichten Einstieg in die Welt des Baselining bekommen. Sie können beide Systeme kostenfrei testen.